Motivation
One recent trend in hiring is for companies to use machine learning models to sort through piles of job applications. This has the obvious advantage (to the company) of reducing the number of hours that recruiters need to spend reading resumes. Algorithmic assessment may also avoid certain biases that human recruiters have, although it is likely to be biased in other ways. Noise or bias in an individual firm’s hiring decision is unfortunate, but one might hope it doesn’t matter too much: strong candidates should be able to find work elsewhere. One concern with algorithmic hiring is that if many companies use the same programs to filter resumes, this can cause correlated errors across jobs, and potentially freeze out some deserving candidates entirely.
One recent paper that tackles this topic is “Algorithmic Monoculture and Social Welfare” by Jon Kleinberg and Manish Raghavan (thanks to Hamsa Bastani for pointing me to this paper). They argue that even if we set aside concerns of systematic bias, algorithmic hiring could actually result in worse outcomes for firms! This post will explain their model and conclude with some of my thoughts.
Model
In their model, there are two firms, each of whom wishes to hire one person. There are \(n\) total candidates. The value of hiring candidate \(i\) is assumed to be \(x_i\) for each firm. However, the firms do not know \(x_i\). Instead, they observe only a noisy ranking of candidates that is correlated with \(x\) (which is assumed to be drawn from a known distribution). Hiring happens as follows. One firm is selected at random to go first, and hires the top-ranked candidate according to its ranking. Then the second firm hires the top remaining candidate according to its ranking (candidates are assumed to accept all positions).
The key choice facing each firm is how to generate its ranking of candidates. Firms can use their own human processes, or can rely on a commonly-available algorithmic ranking. The authors assume that the algorithmic ranking is less noisy (more accurate) than the human processes, and that the rankings produced by human processes are conditionally independent given \(x\). This reduces the hiring problem to a 2x2 game: each firm makes a binary choice, taking into account the choice of the other firm. The authors show that in some cases, this game can be a prisoner’s dilemma:1 both firms choose to use the algorithmic ranking, but they would actually be better off in a world where this ranking was not available and they had to use separate human processes.
Example
To see why firms might be worse off when using a more accurate algorithmic ranking, consider the following stylized example. Each human process either produces the correct list (with probability \(1-q\)), or a uniformly random list (with probability \(q\)). The algorithmic ranking is also either correct (with probability \(1-p\)) or drawn uniformly at random (with probability \(p < q\)).
Suppose that there are \(n = 3\) candidates, with values \(x_1 = 1, x_2 = x_3 = 0\). Then expected combined firm welfare is equal to the probability that candidate 1 is hired. If both firms use the algorithmic ranking, this is \(1 - p/3\) (candidate 1 is hired unless the algorithmic ranking is random and places her at the bottom). However, if both firms use independent human processes, this is \(1 - q^2/3\) (candidate 1 is hired unless both firms have random rankings, in which case each candidate has an equal chance of not being hired). Note that so long as \(p > q^2\), this implies that firms are better off using independent rankings: the probability that both human ranking processes will fail is lower than the probability that the single algorithmic process will.
If outcomes are better for firms when using human processes, why would they choose to use the algorithm? The key is that switching to using a more accurate ranking modestly helps the firm making the change, at the expense of the other firm.
Suppose that firm B is using the algorithmic ranking. If firm A hires first, using the algorithmic ranking increases its utility by \((q-p)\cdot 2/3\). If firm A hires second, it only get utility if firm B does not choose candidate 1 (which occurs with probability \(p \cdot 2/3\)). If this occurs, using the same random ranking to hire gives firm A a 50% chance of success, while using an independent human ranking gives a \(1-q/2\) chance of success. Thus, the expected benefit of switching from a human process to the algorithm is \[ \frac{q-p}{3} + \frac{p}{3}\left(1/2-(1-q/2)\right) = \frac{1}{6}\left(2q-3p+pq \right).\] It is an equilibrium for both to use the algorithm if this term is positive, which occurs whenever \[ p < \frac{2q}{3-q}.\]
plot(NULL,xlim=c(0,1),ylim=c(0,1),xlab='Probability of Human Error',ylab='Probability of Algorithm Error',las=1)
q = 1:100/101
polygon(c(q,rev(q)),c(q^2,2*rev(q)/(3-rev(q))),col = "#6BD7AF")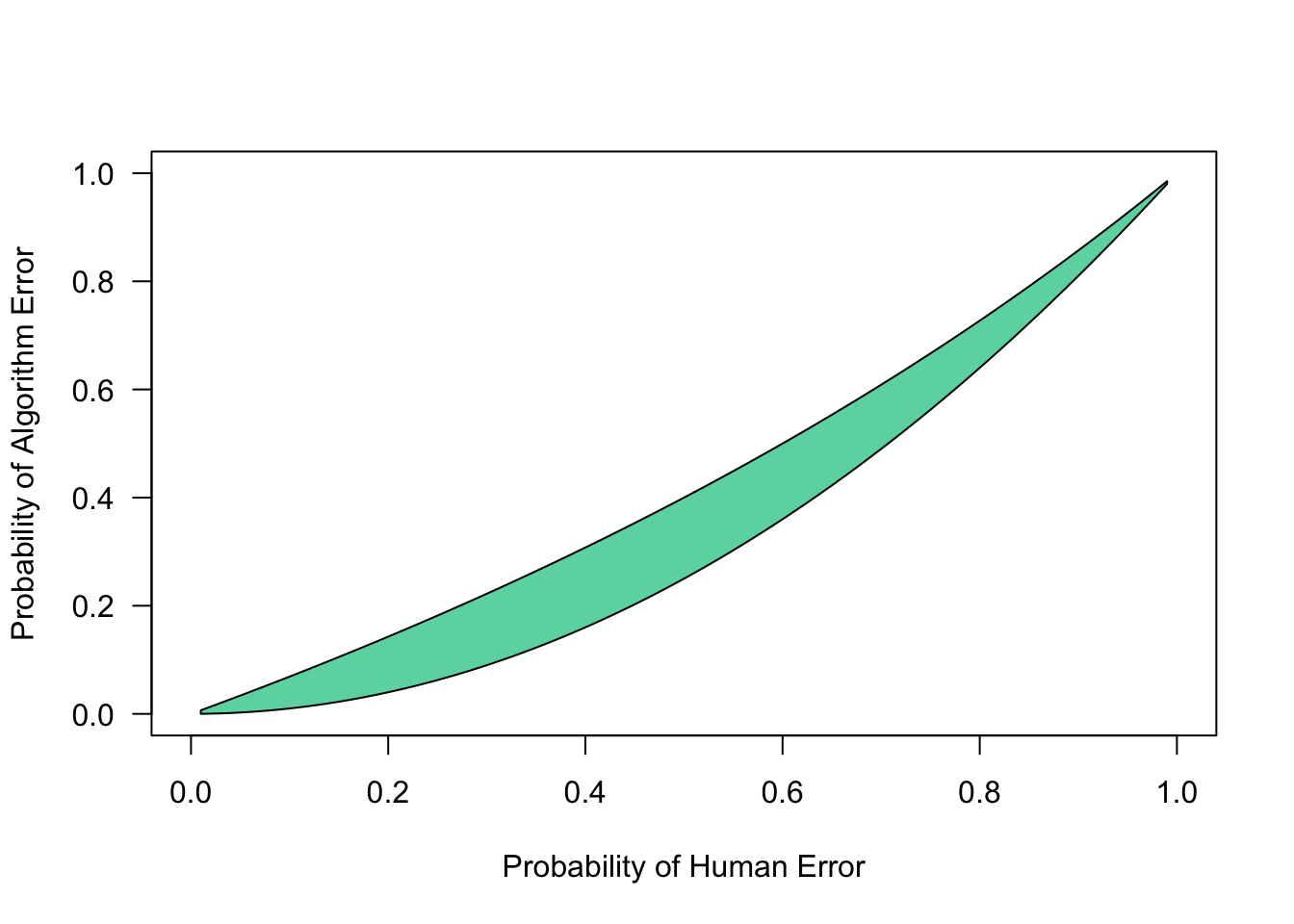
Figure 1: The green region identifies where (i) it is an equilibrium for both firms to use the algorithm, and (ii) the firms are better off when both using human processes.
Benefits and Challenges of Model Generality
If I had tried writing this paper, I probably would have assumed a specific procedure for generating firms’ noisy rankings (like that used in the example above). While that procedure is easy to analyze, it is also very contrived. A more natural assumption might be to use a “random utility model”, which assumes that firm \(j\) ranks according to \(x_i + \epsilon_{ij}\), where \(\epsilon_{ij}\) is random noise. There are also many other possibilities.
Rather than assuming any particular ranking generation process, the authors take a more general approach. They provide results that hold for any ranking procedures and candidate values which satisfy certain conditions. In principle, I appreciate this generality. In practice, I found their conditions difficult to understand, reason about, or even verify in specific examples. While my example above satisfies these conditions, simple variants do not. Their Definition 2 (which I found to be the most opaque) is not satisfied if there are 2 high-quality candidates in my example, rather than only 1 (that is, \(x_1 = x_2 = 1, x_3 = 0\)). Similarly, the authors show that in a random utility model with Gaussian or Laplacian noise, their conditions hold if \(n = 3\) but may not hold if \(n \ge 4\).
Because of the difficulty of verifying their conditions, I have difficulty interpreting their work as anything more than a possibility result. I don’t have much intuition for when the introduction of algorithmic rankings will harm firms, and how significant the resulting loss can be. The authors give an example where algorithmic hiring lowers firm welfare by 4%. In my example above, for any choice of \(p\) and \(q\), algorithmic ranking lowers firm welfare by at most 5.5%. Are there examples where the potential harm is larger? (By contrast, it is easy to construct examples where algorithmic ranking significantly benefits firms.)
The Bigger Picture
Many people probably assume that using algorithmic rankings is (myopically) good for firms: if not, why would they do it? This paper points out that even if each firm prefers to use algorithmic rankings, their adoption may harm other firms in a way that makes the entire industry worse off. This is a somewhat counter-intuitive and interesting result, and I enjoyed thinking about it. I am glad that this paper was written.
Despite this, I emerge unconvinced that this possibility is something I should be worried about. First, as noted above, it’s unclear when this effect will occur, and when it does, I don’t know of any example (within the model) where the loss is large. Furthermore, potential losses from less effective hiring will presumably be at least partially offset by a lower cost of generating the ranking of candidates. (Ranking cost is not captured in the model, but is one of the key forces pushing firms towards the use of algorithms in practice.)
Thus, I emerge thinking that this paper is likely addressing a lower-order concern, and that the first-order concerns with algorithmic hiring are those that I hear more often: that the models that are used are opaque and possibly systematically biased against certain groups. I think the use of algorithms to sort through job candidates is likely here to stay, so understanding this question seems worthy of further study.
They describe the phenomenon as a form of Braess’ paradox. If you haven’t heard of Braess’ paradox, it is super cool, and I urge you to look up a youtube video demonstrating it using springs. However, the situation in this paper seems more directly comparable to the prisoner’s dilemma.↩︎