I recently read the working paper “Design on Matroids” by Isa Hafalir, Fuhito Kojima, Bumin Yenmez, and Koji Yokote. There has been a surge of recent papers looking at matching with distributional constraints. I am trying to stay abreast of this literature, so I was excited to take a look.
Disclaimer. This is part of a series of posts in which I discuss others’ work. My goal with these posts is to organize my thoughts, and share these thoughts with the authors (and anyone else who may be interested). However, I want to make several things clear.
- To prevent the task from being overwhelming, I am not trying to be “comprehensive” (as I would if I officially reviewed the paper). Instead, I will focus on the aspects of the paper that catch my attention.
- While my comments may come across as critical, my goal is to understand and discuss ideas. I would not be writing these posts if I did not find the ideas in the papers interesting or worthwhile.
- These posts are not intended for a general audience. Read only if you are interested in the topic.
Summary
The setting is as follows. There a set of students, a set of schools, and a set of possible contracts \(\mathcal{X}\). Each contract specifies a student, a school, and possibly additional terms. These contracts are strictly ranked according to the order \(\succ\).
However, in addition to the order \(\succ\), there is a “diversity index” which scores how good an assignment is. In particular, each student has a known type. Any assignment induces a “distribution”, which is simply a matrix whose \((t,c)\) entry is the number of type-\(t\) students assigned to school \(c\). The diversity index is a function \(f\) that assigns a real-numbered score to each distribution.
Now suppose that not all contracts are feasible. Instead, we can only select among a subset of contracts \(X \subseteq \mathcal{X}\). Which contracts in \(X\) should be selected? The authors propose using the “Diversity Choice Rule.” This rule first asks, “what is the highest possible diversity index that can be achieved, given \(X\)?” Then, among assignments that achieve this diversity index, it chooses by greedily accepting the highest-ranked contract (according to \(\succ\)) that is compatible with (i) maximizing the diversity index, and (ii) accepting the higher-ranked contracts that we have already committed to.
This Diversity Choice Rule is always well-defined, and always chooses a set of contracts with the highest-possible diversity index. The authors’ goal is to determine when the Diversity Choice Rule has the following nice properties:
- Selects a set of contracts that unambiguously has “higher merit” than any other set with the same diversity index score.
- Is computable in polynomial time.
- Is “path independent” (which implies substitutability).
- Satisfyies the law of aggregate demand.
These properties are not satisfied for every diversity index \(f\), but if \(f\) is “ordinally concave”, then (i), (ii), (iii) hold (see Theorems 1 and 2). If in addition \(f\) is “monotone” then (iv) holds (see Proposition 2).
In some cases, we may not wish to fully maximize the diversity index, but only to ensure that it exceeds some threshold. In this case, the natural approach is to truncate the original diversity index at the desired level, and then apply the Diversity Choice Rule with this new index. The authors go into some detail about conditions under which this approach “works” (satisfies conditions (i)-(iv)).
Reflections
What I Like. I think that the Diversity Choice Rule (which uses greedy merit-based selection to select among assignments that maximize diversity) is a reasonable approach. When \(f\) is ordinally concave, it is basically the only reasonable approach.
Even when \(f\) is not ordinally concave, the Diversity Choice Rule may be a reasonable solution. In fact, Carlos Bonet, Jay Sethuraman and I have a working paper which considers a special case of this model where
- each student is their own type,
- there is only one contract involving each student, and
- the diversity index is binary.
Carlos, Jay, and I argue that the Diversity Choice Rule is the only “explainable” policy (I won’t go into how we formalize this claim).
This paper could potentially help us answer questions that we have grappled with, like “What should the designer do if the contracts \(X\) make it impossible to satisfy their original diversity objective?” For example, suppose the designer may wish to accept a certain number of students of each gender. If not enough women apply, it seems natural that the designer should accept as many women as possible. This can be assured by using a non-binary diversity index.
What I Found Unsatisfying. My first reaction when reading this paper was “this is basically taking what we already know – that greedy selection works well when you have a matroid – and restating it using fancy and opaque terminology.” While I have softened a bit from this uncharitable reaction, it’s hard for me to tell how much of the math in this paper is new or innovative, and how much is just restating known results about matroids. (For what it’s worth, the same critique applies to some of the results in my work with Carlos and Jay.)
I do think that there is value to offering different ways to describe choice functions – especially if these descriptions align with how policymakers think about these issues. Using a “diversity index” may be natural in certain applications. However, if we truly want to take these ideas to practice, a key question that we must confront is, “what are reasonable choices for the diversity index?” There are essentially unlimited possibilities, and this question is almost completely ignored by the present paper.
The authors give several examples (Examples 2-4) of ordinally concave diversity indices, but these are presented very abstractly (devoid of any application). I would like to see a more thorough discussion of possible of diversity indices, including examples that are not ordinally concave, in addition to examples that are.
My suspicion is that many natural rules are not ordinally concave. For example, suppose that we are choosing two candidates to serve as representatives, and get one “diversity point” for each of the following that is true (i) at least one woman, (ii) at least one man, (iii) at least one person under 40, (iv) at least one person over 40. The Diversity Choice Rule with this \(f\) may choose a young woman and an old man ranked #1 and #10, respectively, when candidates #2 and #3 are an older woman and a young man and would also get a maximum score of \(4\).
If the designer’s preferred \(f\) is not ordinally concave, do the authors still recommend the Diversity Choice Rule? Something else? Or do they recommend changing \(f\) to make it ordinally concave?
What I Found Confusing. In this paper, the authors define what it means for a diversity index \(f\) to be
- ordinally concave (Definition 6),
- \(M\)-concave (Definition 10),
- \(M^\natural\)-concave (Definition 11),
- pseudo \(M^\natural\)-concave (Definition 8),
- pseudo \(M^\natural\)-concave\(^+\) (Definition 9),
- semi-strictly pseudo \(M^\natural\)-concave (Definition 12).
While they use a helpful running example (Example 1) to illustrate distinctions between some of these concepts, the sheer number of definitions, along with their similar and not-very-informative names, make these distinctions quite difficult to internalize. Figure 1 shows my attempts to map the relationship between these properties. Ordinal concavity is weaker than all of the other notions except pseudo-\(M^\natural\) concavity.
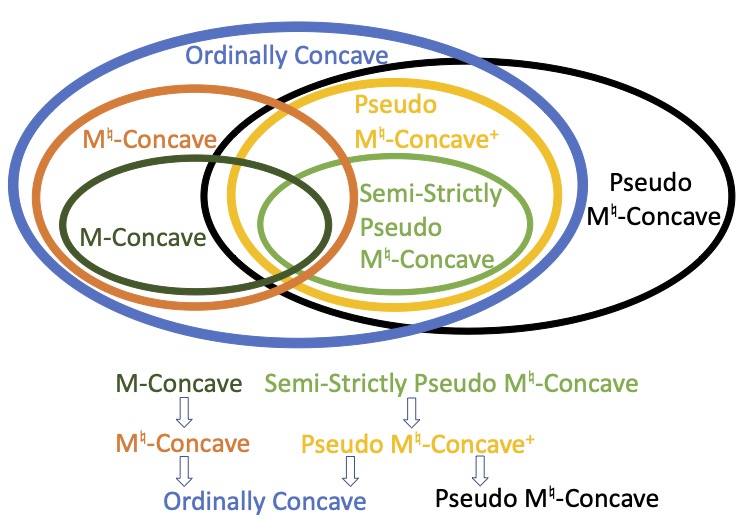
Figure 1: Relationships between concavity notions mentioned in the paper.
This reminds me of the literature on matching with contracts, where substitutability plays a key role in ensuring that deferred-acceptance-like algorithms have good properties. It turns out that slightly weaker notions suffice to ensure some or all of these properties, leading to papers introducing unilateral substitutability, bilateral substitutability, and substitutable completability.
To me, the presence of so many related but distinct conditions is a sign that our current understanding is incomplete. I hope that as our understanding evolves, we can simplify the web of concavity conditions above (none of which has been shown to be necessary to ensure nice properties) to a shorter and easier-to-digest list.