Harry and Tom decide to play a game. They flip a fair coin \(n\) times. Each time the coin comes up heads, there is an opportunity to score. Harry scores a point if the next flip is heads, and Tom scores if the next flip is tails. A player wins if after all \(n\) tosses, their score is higher than their opponents. Who is more likely to win?
A natural instinct is that because each flip is fair (and independent of the past), both players are equally likely to win. But this is wrong! Surprisingly, Tom is more likely to win.
To see this, let’s take the case \(n = 3\). In that case, there are eight possible sequences:
- HHH: Harry 2, Tom 0
- HHT: Harry 1, Tom 1
- HTH: Harry 0, Tom 1
- HTT: Harry 0, Tom 1
- THH: Harry 1, Tom 0
- THT: Harry 0, Tom 1
- TTH: Harry 0, Tom 0
- TTT: Harry 0, Tom 0
Across all 8 sequences, Harry wins 2 times, Tom wins 3 times, and there are 3 ties. If \(n = 4\), we see that Tom still has an advantage:
- HHHH: Harry 3, Tom 0
- HHHT: Harry 2, Tom 1
- HHTH: Harry 1, Tom 1
- HHTT: Harry 1, Tom 1
- HTHH: Harry 1, Tom 1
- HTHT: Harry 0, Tom 2
- HTTH: Harry 0, Tom 1
- HTTT: Harry 0, Tom 1
- THHH: Harry 2, Tom 0
- THHT: Harry 1, Tom 1
- THTH: Harry 0, Tom 1
- THTT: Harry 0, Tom 1
- TTHH: Harry 1, Tom 0
- TTHT: Harry 0, Tom 1
- TTTH: Harry 0, Tom 0
- TTTT: Harry 0, Tom 0
Across all 16 sequences, Harry wins 4 times, Tom wins 6, and there are 6 ties.
What is going on here? First, notice that on average, both players score the same number of points (an average of 0.5 points with \(n = 3\), and \(0.75\) points with \(n = 4\)). This makes sense. However, Harry is more likely to rack up “big wins”, while Tom pulls out 1-0 nail-biters.
The reason for this is that each time Harry scores a point, it creates a new scoring opportunity, giving Tom a chance to make up ground. When Tom scores a point, it reduces the number of scoring opportunities, making it harder for Harry to catch up. For example, when \(n = 3\), if Tom scores a point on the second flip, he will win for sure (as the third flip will not score for either player), while if Harry scores a point on the second flip, Tom gets a chance to tie the game.
The Hot Hand
It is well established that people are bad at making up random sequences. If asked to do so, they tend to alternate between heads and tails too frequently. Put another way, suppose you show someone a series of heads and tails, and ask them if they think the sequence was generated randomly. People will often reject truly random sequences, because these sequences have relatively long streaks of consecutive heads or tails that “feel” non-random.
Let’s connect this to the game of basketball. Players and coaches often speak about a player being “hot”, meaning that they are shooting better than they usually do. It’s certainly true that sometimes players will make a number of shots in a row, but are these streaks any more common than what we would expect from repeatedly flipping a coin?
A famous study by Gilovich, Vallone, and Tversky (henceforth GVT) tries to assess this using several sources of data. We will focus on a controlled shooting experiment that they did with college basketball players, in which there was no defense to confound things. They got make/miss data in which 26 players each took 100 shots. They then asked, does being “hot” increase the probability of making the next shot?
To answer this question, you need to define what it means for a player to be “hot”. GVT defined this as a string of \(k\) consecutive made shots. Similarly, a player is “cold” if they have just missed \(k\) consecutive shots. GVT sought to compare success rate when hot to success rate when cold.
Let’s make this concrete. Suppose \(k = 2\) and the sequence is TTHTHHHTHHTTHT, with T representing a miss and H a make. During this sequence, the player was hot a total of three times, of which they made 1 of those shots, so we calculate \(\hat{P}(Make | Hot) = 1/3 \approx 33\%\). Meanwhile, the player was cold twice, and made both of those shots, so \(\hat{P}(Make | Cold) = 2/2 = 100\%\).
It seems reasonable to believe that if the data itself is iid, then on average, \(\hat{P}(Make | Hot)\) should equal \(\hat{P}(Make | Cold)\). Reasonable, but wrong!
I’m going to try to explain why this is wrong in three ways. First, with an example (calculations for the case \(k = 1, n = 3\)). Second, with an analysis of this example that uses mathy terms such as “expectation” and “unbiased”. Finally, with an explanation that uses more “intuitive” language, and connects this intuition back to our opening example. Hopefully you find at least one of these helpful!
\[\begin{array}{|c|c c| c c | } \hline \textbf{Sequence} & \hat{P}(Make|Hot) & & \hat{P}(Make|Cold) & \\ \hline HHH & 100\% & (2/2) & NA & (0/0) \\ HHT & 50\% & (1/2) & NA & (0/0)\\ HTH & 0\% & (0/1) & 100\% & (1/1) \\ HTT & 0\% & (0/1) & 0\% & (0/1) \\ THH & 100\% & (1/1) & 100\% & (1/1) \\ THT & 0\% & (0/1) & 100\% & (1/1) \\ TTH & NA & (0/0) & 50\% & (1/2)\\ TTT & NA & (0/0) & 0\% & (0/2)\\ \hline \textbf{Avg} & 41.7\% & & 58.3\% & \\ \hline \end{array} \] Let’s take a look at what is going on here. Notice that on some sequences, \(\hat{P}(Make|Hot)\) is not well-defined, because the shooter was never hot. Thus, when I write \(\mathbb{E}[\hat{P}(Make|Hot)]\), I actually mean the expectation of this quantity, conditioned on being hot at least once. To get this, we calculate \((100\% + 50\% + 0\% + 0\% + 100\% + 0\%)/6 = 41.7\%\).
The source of the bias is that we are taking an expectation of the ratio “# hot makes” to “# times hot”. The expected number of hot makes is the same as the expected number of hot misses, so if the denominator (# times hot) were the same for all sequences, we would have an unbiased estimate. In reality, though, the denominator varies across sequences, and is larger for sequences with more makes. Specifically, the hot makes are concentrated in sequences where the denominator equals two (HHH and HHT), while the hot misses are concentrated in sequences where the denominator equals one.
That was a lot of math talk. Let’s try translating it to English. The reason for the bias is similar to that for the opening problem with Harry and Tom.
Every time a player is hot and makes a shot, they are still hot, and have a chance to bring \(\hat{P}(Make | Hot)\) down. Put another way, the made shot will be combined with the next shot, reducing its influence on the overall average \(\hat{P}(Make | Hot)\). Similarly, every time a player is cold and misses a shot, they are still cold and have a chance to bring \(\hat{P}(Make | Cold)\) up.
As a result of this, if data is iid with probability \(p\) of success, \(\mathbb{E}[\hat{P}(Make | Hot)]\) is less than \(p\), while \(\mathbb{E}[\hat{P}(Make | Cold)]\) is greater than \(p\). How large is the bias? That depends on the streak length \(k\), the sequence length \(n\), and the probability of success \(p\). In general, the bias is largest when players are only hot or cold a few times. In other words, increasing \(k\) tends to increase the bias, while increasing \(n\) tends to reduce it. We can explore the magnitude of the bias with the following code.
#shots is a binary vector (0 = miss, 1 = make)
#A player is "hot" if they have made k consecutive shots, "cold" if missed k consecutive shots
#Returns a matrix result, where e.g. result['Hot','Make'] is the number of makes when hot
streak_analysis <- function(shots, k) {
n <- length(shots)
#Identify shots when the player was hot and cold
if(k == 1) {
hot <- c(FALSE, shots[1:(n-1)] == 1)
cold <- c(FALSE, shots[1:(n-1)] == 0)
} else {
shot_sequences <- embed(shots, k+1)
current_shots <- shot_sequences[, 1]
prev_k_shots <- shot_sequences[, 2:(k+1)]
# Pad with FALSE for first k observations
hot <- c(rep(FALSE, k), rowSums(prev_k_shots) == k)
cold <- c(rep(FALSE, k), rowSums(prev_k_shots) == 0)
}
#Create and return 2x2 table of results
hot_makes <- sum(shots[hot] == 1)
hot_misses <- sum(shots[hot] == 0)
cold_makes <- sum(shots[cold] == 1)
cold_misses <- sum(shots[cold] == 0)
return(matrix(c(hot_makes, cold_makes, hot_misses, cold_misses),
nrow = 2,
dimnames = list(c("Hot", "Cold"), c("Make", "Miss"))))
}
proportions = function(counts){
x = c(counts['Hot','Make']/sum(counts['Hot',]),counts['Cold','Make']/sum(counts['Cold',]))
names(x) = c('Hot','Cold')
return(x)
}
set.seed(2024)
n_shots= 100
n_players = 10000
streak_length = 3
shots = matrix(runif(n_shots*n_players)<0.5,nrow=n_shots) #Generate random shot outcomes
#data['Hot',i] is P(Make | Hot) for player i; data['Cold',i] is P(Make | Cold) for player i
data = apply(shots,2,function(x){return(proportions(streak_analysis(x,streak_length)))})
mean(data['Hot',],na.rm=TRUE) #Average of P(Make | Hot)## [1] 0.4628902mean(data['Cold',],na.rm=TRUE) #Average of P(Make | Cold)## [1] 0.5408251This shows that when \(p = 0.5\), each player takes \(n = 100\) shots, and hot and cold are defined by streaks of length \(k = 3\), \(\mathbb{E}[P(Make | Hot)]\) is approximately \(0.46\), and \(\mathbb{E}[P(Make | Cold)]\) is approximately \(0.54\).
Conclusions
Although the original study was conducted in 1985 and generated a lot of attention and follow-up work, the error was not caught for over 30 years, until it was pointed out by Miller and Sanjurjo. Their conclusion (which I agree with) is that the bias in the procedure used by GVT is large enough to overturn their null results. Feel free to read these papers for a more thorough discussion and analysis. The raw shooting data from the original study is available here.
What do I make of this? Well, one simple take-away is that probability and statistics can be very tricky! It’s easy for me to see how this mistake occurred. It seems so natural to assume that for an iid sequence, \(\hat{P}(Make | Hot)\) should (on average) equal \(\hat{P}(Make | Cold)\).
On the other hand, I’m somewhat surprised that the error wasn’t caught sooner. After all, it is very easy to generate random data, and notice that something seems wrong (that is, \(\mathbb{E}[P(Make | Hot)]\) and \(\mathbb{E}[P(Make | Cold)]\) are not equal to \(p\)). I did it in about 30 lines of code above. If this paper had been written in the modern age, I suspect that the authors would have done this. Back in 1985, simulations were not so common.
I think the failure of others to catch the error is probably due to multiple factors. First, when doing a replication, you often try to stay as close as possible to the original. There are many ways one could have defined and tested for the “hot hand”, but once GVT defined a procedure, people probably just followed this procedure (using new data) without really thinking about whether the procedure made sense.
Second, the conclusion of GVT was probably appealing to many psychologists, preventing it from facing scrutiny. We know of lots of ways in which people are superstitious and/or misunderstand probability – if I were reading this paper, I would suspect that the “hot hand” isn’t real even before being presented with the evidence. As a result, I wouldn’t look all that closely at the evidence.
As a math-oriented person, the next question would be “what analysis should we do instead?” Inspired by the game in the opening section, one might be tempted to just count total successes when hot, and compare it to total successes when cold (aggregated across all players). If all players are equally good shooters, this correction would work. Otherwise, it could fail miserably. For an extreme example, suppose that one player shoots 90% and another shoots 10%. Most hot streaks would involve the 90% shooter (and thus would be followed by a make), while most cold streaks would involve the 10% shooter (and thus would be followed by a miss). In other words, it would look like the hot hand was real, even if both player’s shots were iid.
A much better approach is to use what is known in statistics as a permutation test. These are very cool and there’s a lot to say about them, so I hope to return to this topic in a future post.
Appendix
Let’s return briefly to the game played by Tom and Harry. As we saw, when the coin was unbiased, the game itself was biased in favor of Tom. However, if the coin always came up heads, then of course Harry would always win. Thus, we can ask the question, “how much bias does the coin have to have to make the game fair?”
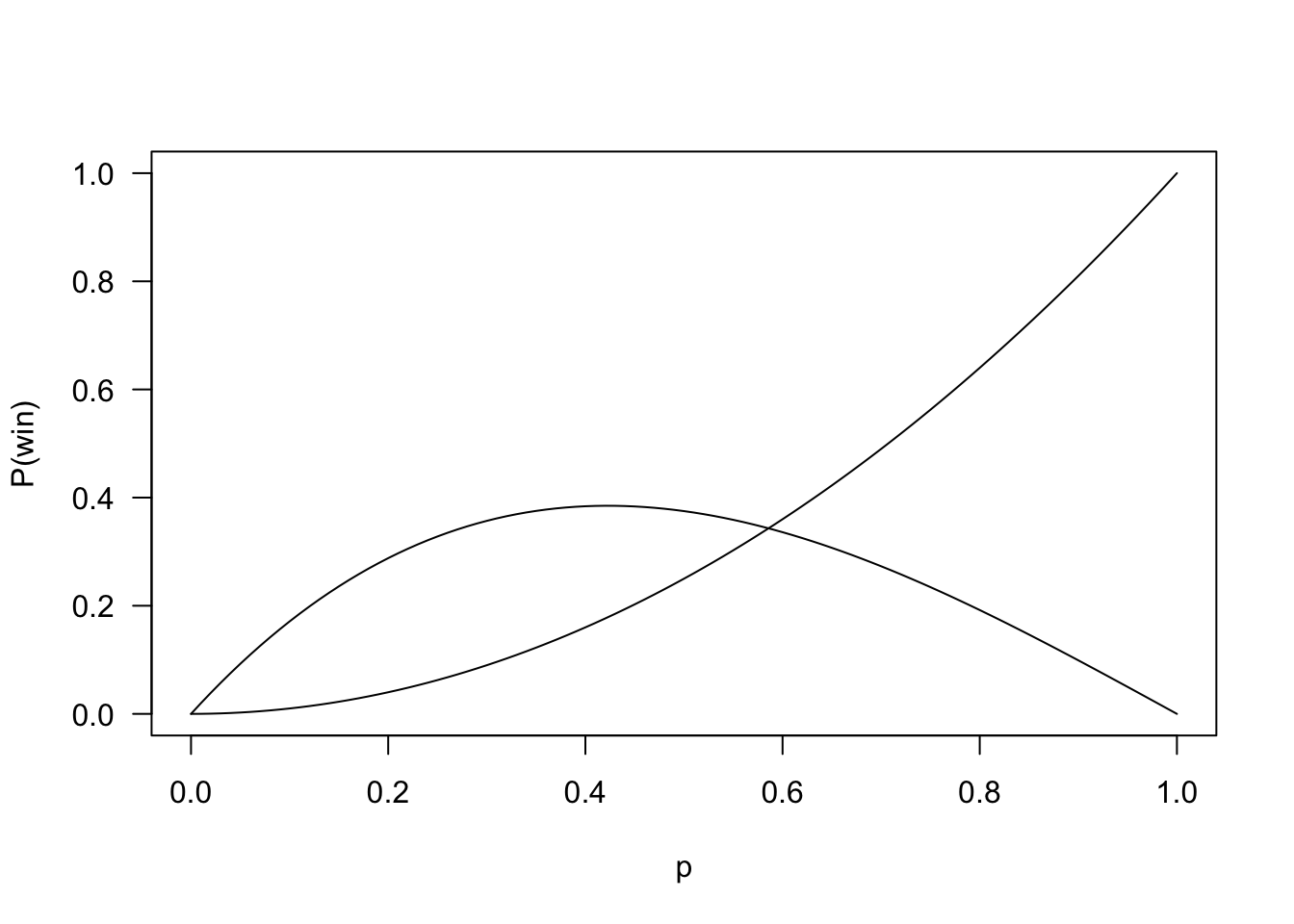
When \(n = 3\), this is a fairly simple algebra problem: if the coin has probability \(p\) of coming up heads, then the total probability of the three sequences on which Tom wins (\(THT, HTT, HTH\)) is \(2p(1-p)^2+p^2(1-p)\). The probability of the two sequences on which Harry wins (\(THH, HHH\)) is \(p^3 + p^2(1-p)\). Setting these equal, rearranging, and applying the quadratic formula yields \(p = 2 - \sqrt(2) \approx 0.586\). In other words, Tom is more likely to win so long as the probability of heads less than \(2 - \sqrt(2)\).
We can also consider a different model, inspired by the hot hand idea. Suppose that the first flip is equally likely to be heads or tails. From there, each flip is the same as the previous one with probability \(q\), and is different from the previous one with probability \(1-q\). For any \(q \in (0,1)\), in the long run, half of flips will be heads and half will be tails. When \(q > 1/2\), we have a “hot hand” effect: heads are more likely after a previous heads. Note that if \(q \approx 1\), Harry wins half the time (when the first flip is heads), while Tom never wins (if the first flip is tails, neither player will have the opportunity to score points). We might wonder “how strong does the hot hand effect have to be in order for Harry to be favored?” Now, the probability of a winning sequence for Tom is \(q(1-q)/2 + (1-q)^2\), and the probability of a winning sequence for Harry is \(q(1-q)/2+q^2/2 = q/2\). After some algebra, we again get that the break-even point is \(q = 2 - \sqrt{2}\).
#Calculate number of made and missed shots when hot
#Hot is defined as having made previous streak_length shots
score = function(streak_length=1){
return(function(s){ #s is a sequence of outcomes
hot = 1+which(filter(as.numeric(s[-length(s)]), rep(1, streak_length), sides = 1) == streak_length) #Identify positions that follow k consecutive makes
score = c(sum(s[hot]),sum(1-s[hot]))
names(score) = c('made_shots_when_hot','missed_shots_when_hot')
return(score)
})
}
#Calculate probability of observing sequence s, if shots are iid with success prob p
accuracy_likelihood = function(p){
return(function(s){
return(p^sum(s)*(1-p)^(sum(1-s)))
})
}
#Calculate probability of observing sequence s, if first shot is 50-50, and subsequent shots match preceding outcome with probability q
hot_hand_likelihood = function(q){
return(function(s){
return(q^(length(s)-1)*((1-q)/q)^sum(abs(diff(s)))/2)
})
}
#Given a number of flips n, a likelihood function that gives probability of each sequence of length n, and a score function that calculates score for each sequence of length n, calculate the probability that each player wins
calculate_win_probability = function(n,likelihood_function,scoring_function){
S = expand.grid(replicate(n, 0:1, simplify = FALSE))
Q = apply(S,1,likelihood_function) #Should give vector where Q[i] = probability of sequence S[i,], given p (so sum(Q) = 1)
score = t(apply(S,1,scoring_function)) #Scoring each sequence
hh = sum((score[,1]>score[,2])*Q,na.rm=TRUE)
ht = sum((score[,1]<score[,2])*Q,na.rm=TRUE)
x = c(hh,ht,1-hh-ht)
names(x) = c('HH','HT','TIE')
return(x)
}
n = 3
plot(Vectorize(function(p){ #Plotting win probability for player 1 (Harry)
return(calculate_win_probability(n,accuracy_likelihood(p),score(1))[1])
}),xlab='p',ylab='P(win)',las=1)
plot(Vectorize(function(p){ #Plotting win probability for player 2 (Tom)
return(calculate_win_probability(n,accuracy_likelihood(p),score(1))[2])
}),add=TRUE)