3 Their Algorithm and Results
The goal of the paper is to generalize the median strategy to arbitrary \(k > 1\).
3.1 Key Step #1: Balancing Two Risks
When setting \(t\), we face a tradeoff. Set \(t\) too high, and we might not keep very many items. Set \(t\) too low, and we might might take \(k\) items early, and miss out on a valuable item later. The crux of the algorithm will be to find a way to balance these concerns. Define \[\begin{align} D_t(V) & = \sum_{i = 1}^n {\bf 1}(V_i > t) \\ \delta_k(t,F) & = \mathbb{P}_{V \sim F}(D_t(V) < k)\\ \mu_k(t,F) & = \frac{1}{k} \mathbb{E}_{V \sim F}[\min(D_t(V),k)] \end{align}\]That is, \(D_t(V)\) is the “demand” at \(t\) (number of values above \(t\)), \(\delta_k\) gives the probability of keeping fewer than \(k\) items when using threshold \(t\), and \(\mu_k\) is our expected “fill rate” (the expected number of items that we keep, divided by \(k\)). The following result relates the performance of \(ST_k^t\) to \(\delta_k\) and \(\mu_k\).
The key idea is that when we consider any value \(V_i\), the probability that we have not yet kept \(k\) items (and could therefore choose \(V_i\) if we wish) is at least \(\delta_k\). Meanwhile, if \(\mu_k\) is high, then we don’t lose much due to keeping too few items.
An Algorithm For Choosing \(t\). Proposition 3.1 immediately implies the following. \[ \inf_{{\bf F}} \sup_{t} \frac{ST_k^t({\bf F})}{OMN_k({\bf F})} \geq \inf_{{\bf F}} \sup_{t} \min\left(\delta_k(t,{\bf F}),\mu_k(t,{\bf F})\right).\]
This suggests an algorithm for choosing \(t\): since \(\delta_k\) is increasing in \(t\), and \(\mu_k\) is decreasing in \(t\), the supremum is obtained at a threshold \(t\) such that \(\delta_k(t,{\bf F}) = \mu_k(t,{\bf F})\). When \(k = 1\), we have \(\mu_1(t,{\bf F}) = 1 - \delta_1(t,{\bf F})\) for all \(t\) and \({\bf F}\). This implies that at their crossing point, both are equal to \(1/2\). In other words, we set a threshold \(t\) such that our probability of keeping any item is \(1/2\): this is the median algorithm of Samuel-Cahn (1984)!
Notes on the Proof. The proof establishes a lower bound on \(ST_k^t({\bf F})\), expressed in terms of the following function:1 \[\begin{equation} U(t,{\bf F}) = \mathbb{E}_{V \sim {\bf F}}\left[\sum_{i = 1}^n\max(V_i - t,0) \right] = \sum_{i = 1}^n \int_t^\infty(1 - F_i(x))dx. \end{equation}\] The second inequality above uses my one of my favorite facts: for a non-negative random variable \(X\), \[\mathbb{E}[X] = \int_0^\infty \mathbb{P}(X > x) dx.\]Jointly, Lemmas 3.1 and 3.2 imply Proposition 3.1. In fact, the resulting guarantee holds even against the benchmark of an LP relaxation of OMN, which is permitted to keep at most \(k\) values in expectation, rather than for every realization. This relaxation sets a threshold \(t_k^{LP}({\bf F})\) such that the expected demand is equal to \(k\), and then accepts all such items. Its expected payout is \[LP_k({\bf F}) = \mathbb{E}_{V \sim {\bf F}} \left[\sum_{i = 1}^n V_i {\bf 1}(V_i > t_k^{LP}({\bf F})) \right] = \min_t B_k(t,{\bf F}).\]
3.2 Key Step #2: Determining the Worst Case
We now need to find a worst case choice of the distributions \({\bf F}\). One key advantage of this analysis is that the functions \(\delta_k\) and \(\mu_k\) depend only on the distribution of \(D_t(V)\), which is a sum of independent Bernoulli random variables. Therefore, instead of optimizing over the space of all distributions, it is enough to optimize over the success probabilities (referred to as “biases” in the paper) \(b_i = (1 - F_i(t))\).
The most involved step in their analysis is to show that the worst case is when the biases are equal, and \(D_t\) follows a binomial distribution. We let \(X_{n,p}\) denote a binomial random variable with \(n\) trials and success probability \(p\).
We can use the following code to compute the values \(\gamma_{k,n}\).
delta_binom = function(n,k,p){
return(pbinom(k-1,n,p))
}
mu_binom = function(n,k,p){
prob = dbinom(0:(k-1),n,p)
prob = c(prob,1-sum(prob))
return(sum(prob*c(0:k))/k)
}
guarantee_at_p = function(n,k){
return(Vectorize(function(p){return(min(delta_binom(n,k,p),mu_binom(n,k,p)))}))
}
guarantee_finite = Vectorize(function(n,k){
return(optimize(guarantee_at_p(n,k),interval=c(0,1),maximum=TRUE)$objective)
})
kVals = c(2:4)
colors = rainbow(length(kVals))
nMax = 10
plot(NULL,xlim=c(2,nMax),ylim=c(0.5,0.75),las=1,xlab='n',ylab='',main='Performance Guarantee')
for(i in 1:length(kVals)){
lines(c(kVals[i]:nMax),guarantee_finite(c(kVals[i]:nMax),kVals[i]),col=colors[i])
}
legend(2,.58,col=colors,lty=rep('solid',length(kVals)),legend = kVals)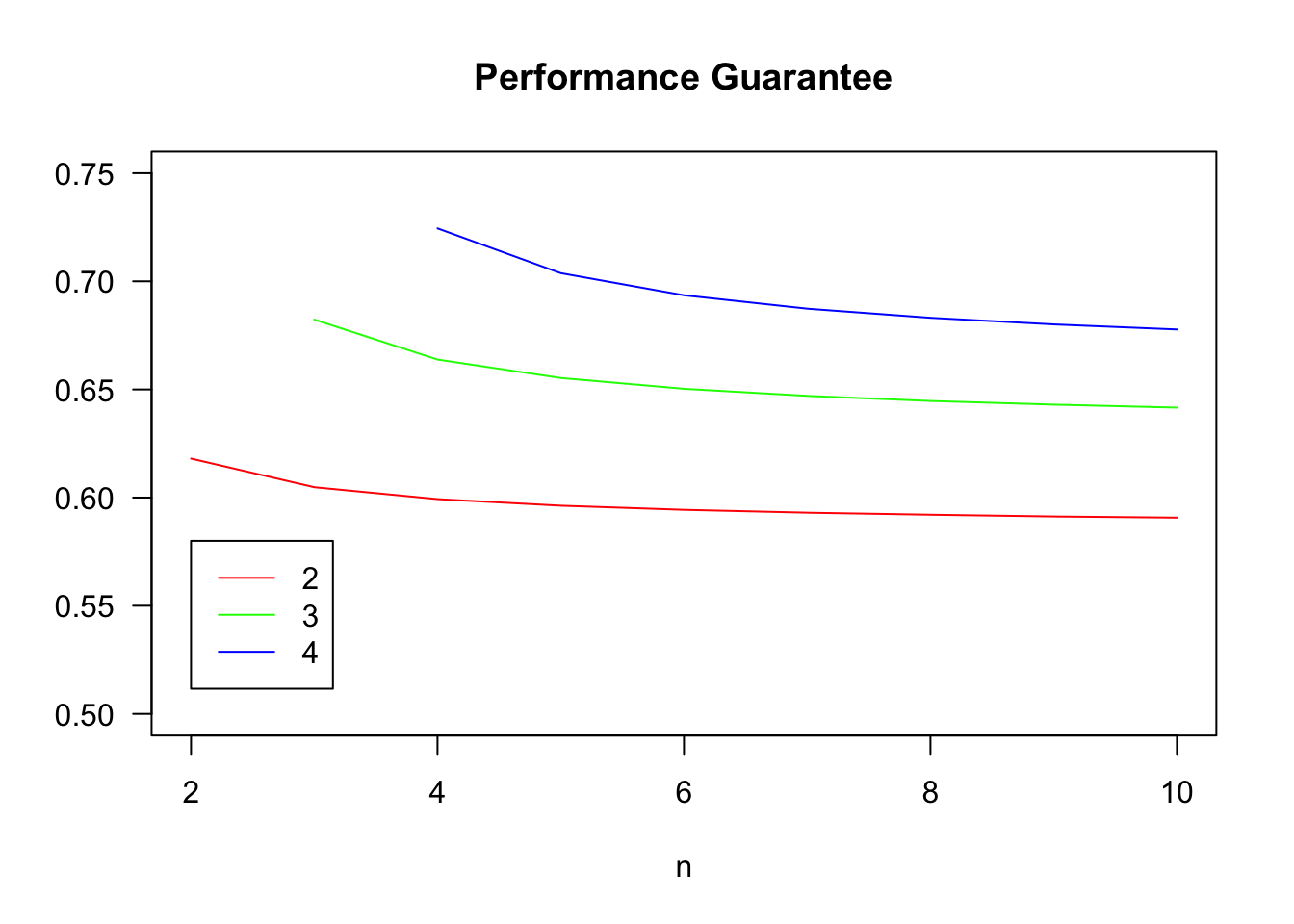
The guarantee \(\gamma_{k,n}\) is increasing in \(k\) and decreasing in \(n\), but depends much more on \(k\) than \(n\). If we take \(n \rightarrow \infty\), the binomial distribution becomes a Poisson, and we obtain bounds that hold for all \(n\).
delta_pois = function(lambda,k){return(ppois(k-1,lambda))}
mu_pois = function(lambda,k){
prob = dpois(0:(k-1),lambda)
prob = c(prob,1-sum(prob))
return(sum(prob*c(0:k))/k)
}
guarantee_at_lambda = function(k){
return(Vectorize(function(lambda){
return(min(delta_pois(lambda,k),mu_pois(lambda,k)))
}))
}
guarantee_pois = Vectorize(function(k){
return(optimize(guarantee_at_lambda(k),interval=c(0,k),maximum=TRUE)$objective)
})
kVals = c(1:10)
round(guarantee_pois(kVals),3)## [1] 0.500 0.586 0.631 0.660 0.682 0.699 0.713 0.724 0.734 0.742For \(k = 1\), we recover the guarantee of \(1/2\), but this paper provides the first guarantee above \(1/2\) for \(k = 2\). The guarantee converges to \(1\) (at an optimal rate) as \(k \rightarrow \infty\).